Focal Loss for Dense Object Detection(Retinanet paper) 논문 리뷰
사진에서 얻어가야하는 내용

- Focal Loss는 아주 많은 easy background example가 있는 상황에서 매우 정확한 밀도의 물체 감지기를 훈련할 수 있게 해준다.
사진에서 알아가야할 내용

- RetinaNet을 사용해 최대 40.8 AP까지 달성했다는 것이다.
AP의 정의
- COCO data 사용시 정확도
Focal loss
- 학습 시 앞/배경 클래스 사이의 심한 불균형을 해결하기 위해 나왔다.
cross entropy (CE) loss for binary classification
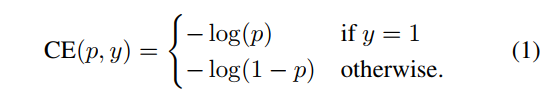
- y ∈ {±1}은 binary classification 를 지정하고 p ∈ [0, 1]은 라벨 y = 1인 클래스에 대한 모델의 추정 확률이다.
notational convenience을 위해서
define pt:

pt를 구한 후 CE(p, y) = CE(pt) = − log(pt )로 인식한다.
Balanced Cross Entropy
α-balanced CE loss

조건
- 클래스 1의 경우 가중치 α ∈ [0, 1]
- 클래스 −1의 경우 1 − α
"α"특징
- α는 역클래스 빈도로 설정되거나 교차 검증을 통해 설정되는 하이퍼파라미터로 처리될 수 있습니다.
- 표기상으로 pt를 정의한 방법과 유사하게 αt를 정의합니다.
Focal Loss Definition
대신, 우리는 손실 함수를 재구성하여 쉬운 예제의 가중치를 낮추고 어려운 음성 예제에 대한 훈련에 집중하도록 제안합니다.
Focal Loss는 그림 1의 여러 γ 값에 대해 시각화됩니다. 우리는 Focal Loss의 두 가지 속성을 주목한다:

- 예제가 잘못 분류되고 가 작을 때, 조정 요인은 1이 되며 손실에 영향이 없습니다. pt→1일 때, 이 요인은 0이 되어 잘 분류된 예제의 손실이 감소한다.
- 집중 매개변수 γ는 easy example의 다운 가중치 비율을 조정합니다. 일 때 FL은 CE와 동일하며, γ가 증가함에 따라 조정 요인의 효과도 증가한다(우리의 실험에서는 가 가장 잘 작동함을 발견했다).
α-balanced variant of the focal loss

이 형태를 논문에서 사용했으며, 이는 비균형 형태보다 약간 향상된 정확도를 제공합니다.
Class Imbalance and Model Initialization
Initialization해야하는 이유
- class imbalance가 존재하는 경우 빈번한 클래스로 인한 손실이 전체 손실을 압도하여 초기 훈련의 imbalance을 일으킬 수 있습니다.
- 논문에서는 π = 0.01으로 initialization(초기화)해서 사용한다.
Class Imbalance and Two-stage Detectors
특징
2stage detector는 종종 다음을 사용하지 않고 crossentropy loss로 훈련된다.
두 가지 메커니즘
사용 이유
- class imbalace를 해결
1. 2단계 계단식 메커니즘 특징
- 객체 제안 메커니즘
- 거의 무한한 가능한 개체 위치 집합을 1,000개 또는 2,000개로 줄인다.
- 선택된 제안이 무작위가 아니라 실제 개체 위치와 일치할 가능성이 높기 때문에 대부분의 쉬운 부정이 제거된다.
2. 편향된 미니배치 메커니즘 특징
- 훈련할 때 편향된 샘플링은 일반적으로 예를 들어 positive example과 negative example 1:3 비율을 포함하는 미니 배치를 구성하는 데 사용된다.
- α- 샘플링을 통해 구현되는 균형 요소. 제안된 초점 손실은 손실 기능을 통해 직접 1단계 감지 시스템에서 이러한 메커니즘을 해결하도록 설계되었다.

Feature Pyramid Network Backbone
Feature Pyramid Network (FPN)
- RetinaNet의 backbone network이다.
- 피라미드의 각 레벨은 다른 규모의 객체를 감지하는 데 사용할 수 있다.
- FPN은 완전 합성곱 네트워크(FCN)에서 다중 규모 예측을 개선한다. 이는 RPN 및 DeepMask 스타일 제안, Fast R-CNN 또는 Mask R-CNN과 같은 2단계 감지기에서 다양한 크기의 이미지를 감지할 수 있음을 의미하는 것으로 보여진다.
FPN이란?
표준 합성곱 신경망에 상향식 경로와 측면 연결을 추가하여 단일 해상도 입력 이미지에서 풍부한 다중 규모 피처 피라미드를 효율적으로 구성하는 것이다(그림 3(a)-(b) 참조)
anchor
IoU threshold of 0.5
- [0, 0.4)의 IoU는 background라고 판단
- [0.4, 0.5]의 IoU를 가지는 Anchors Box는 학습 도중에 무시된다.
- box ratio: 1:2,1:1,2:1
RetinaNet
특징
- 단일 통합 네트워크
- 피라미드 구조
- 하향식을 사용해 convolution network를 강화한다.
두 개의 subnet
subnet1(Classification Subnet)
특징
- 출력에 대해 개체 분류와 컨볼루션 개체 분류를 수행한다.
- 분류 서브넷은 각 항목의 각 공간 위치에 객체가 존재할 확률을 예측한다.
구조
- 주어진 피라미드 레벨에서 C 채널이 포함된 입력 특성 맵을 가져오면 서브넷은 4개의 3×3 전환 레이어를 적용한다.
- 각 레이어에는 C 필터가 있고 각 레이어에는 ReLU 활성화가 적용되며 그 뒤에는 KA 필터가 있는 3×3 전환 레이어가 적용된다.
- 마지막으로 Sigmoid 활성화가 첨부되어 공간 위치당 KA binary prediction을 출력한다.
* 대부분의 실험에서는 C = 256과 A = 9를 사용한다.
subnet2(Box Regression Subnet)
특징
- 각 피라미드 수준에 작은 FCN을 연결해 convolution 경계상자 회귀를 수행한다.
- 적은 수의 매개 변수를 사용하는 class-independent bounding box regressor (클래스 독립적 경계 상자 회귀자)를 사용하며 동일하게 효과적인 것으로 나타났다.
- Object classification subnet 과 box regression subnet은 공통 구조를 공유하지만 별도의 매개변수를 사용한다.
- anchor박스(객체 위치를 예측해 박스로 표현하는 부분)을 조절하는 부분이라 생각된다.(이 문장은 내 생각이다. 논문엔 없다.)
Inference and Training
- positive와 negative가 너무 차이가 나서 class imbalance현상이 발생한다.
- Inference(추론)에는 단순히 네트워크를 통해 이미지를 전달하는 작업이 포함된다.
Inference
과정
1. 신뢰도 설정
- 0.05로 임계값으로 설정한다. 이는 속도를 올리기 위함이다.
2. 상자 예측만 디코딩
- FPN 수준당 최대 1,000개의 최고 점수 예측한다.
3. 최종 탐지가 생성
- 모든 수준의 상위 예측이 병합되고 임계값 0.5의 비최대 억제가 적용되어 생성된다.
Focal Loss
용도
* 분류 서브넷의 출력에 대한 손실로 사용한다.
AP비교

- γ는 [.25, .75] 범위에 있으며, α는 [.01, .999]로 설정된다.
- γ = 2.0, α = .25를 사용하며, 이는 최상의 정확도를 보인다.
Optimization(최적화)
훈련
- RetinaNet은 8개의 GPU에 걸쳐 동기화된 확률적 경사 하강법(SGD)으로 훈련된다.
- 미니배치당 총 16개의 이미지(각 GPU당 2개의 이미지)를 사용한다.
- iterations(반복) = 90k
learning rate
- 기본 설정 값은 0.01이다.
- learning rate는 60k 반복에서 10배 감소하고, 80k 반복에서 다시 10배 감소한다.
데이터 증대(data augmentation) 방법
- 수평 이미지 뒤집기만 사용한다.
기타정보
- 가중치 감소(weight decay)는 0.0001
- 모멘텀(momentum)은 0.9
- 훈련 손실 함수 = 표준 L1 loss + Focal Loss (둘 다 박스 회귀(box regression)에 사용)
Anchor Density
One-stage detection system
- 가장 중요한 설계 요소 중 하나는 가능한 이미지 상자의 공간을 얼마나 조밀하게 포함하는 지이다.
- "anchor"를 사용하는 접근방식에서 좋은 결과를 얻기 위해 고정된 sampling grid를 사용한다.
Two-stage detection
- position pooling 작업을 사용하여 모든 position, scale 및 aspect ratio에서 상자를 분류할 수 있다.
앵커 수를 6~9개 이상으로 유지한다.
- 이유: 이 이상 늘려도 더 이상의 이득은 나타나지 않았기 때문이다.
- 유지하는 의미: 2단계 시스템은 이미지에서 임의의 상자를 분류할 수 있지만 밀도에 따른 성능 포화는 2단계 시스템의 더 높은 잠재적 밀도가 이점을 제공하지 못 할 수 있음을 의미한다.
Speed versus Accuracy
추론속도가 느려지는 경우
- backbone networks가 클수록 정확도는 높아지는 경우
- 입력 이미지 크기가 커지는 경우
Conclusion
- class imbalance은 1단계 객체 감지기의 성능이 최고 수준의 2단계 방법을 뛰어넘지 못하게 하는 주요 장애물이다.
- Focal Loss는 hard negative example에 대한 학습에 집중하기 위해 cross entropy loss에 변조 항을 적용합니다.(α-balanced variant of the focal loss부분 참고)
- 완전히 convolution된 1단계 검출기를 설계해 그 효율성을 입증하고 이것이 최첨단 정확도와 속도를 달성한다는 것을 보여주는 광범 위한 실험 분석을 보고한다.
참고
[논문리뷰] RetinaNet: Focal Loss for Dense Object Detection